
Once a company decides to build AI, the next question is where to begin. It is a question with real money behind it. McKinsey reports that 88% of organizations now use AI in at least one function, yet fewer than 40% have scaled it beyond a pilot. The companies pulling ahead are the ones who chose the right first place to start and built it well.
The instinct is to start where AI feels most exciting, or where a vendor demo looked most impressive. That is the wrong way to choose. The better approach is to start where the conditions for success already exist, because the first build sets the pattern for everything that follows.
Choose the place where you are most likely to succeed
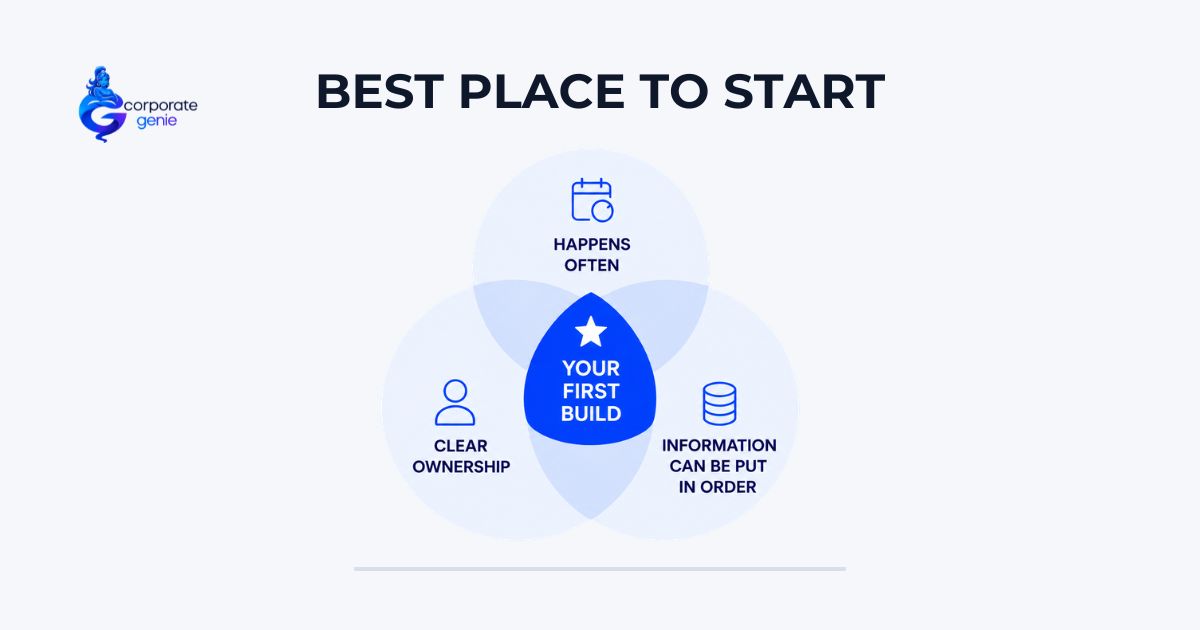
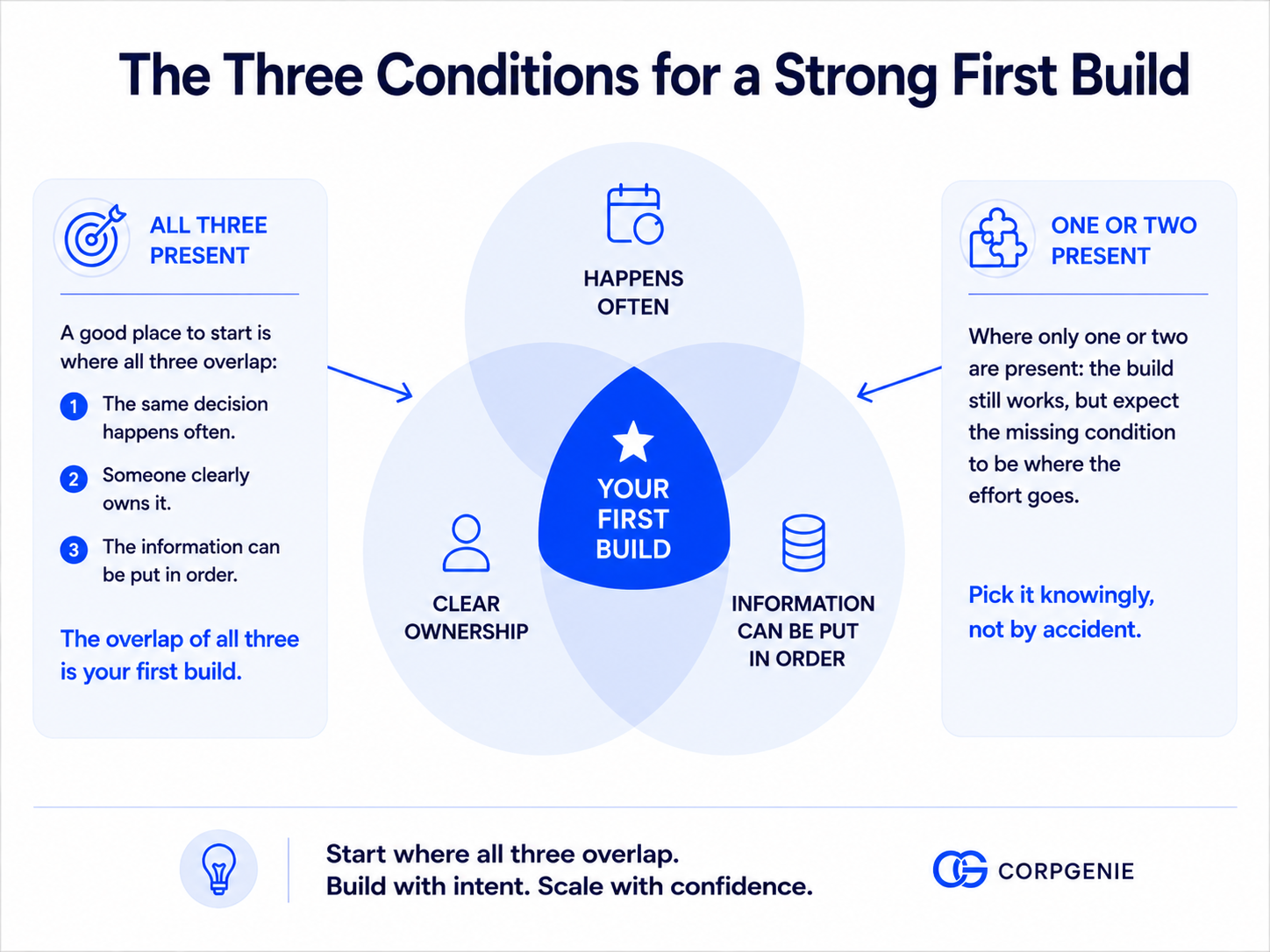
The strongest place to begin is where three conditions line up at once. These are the same conditions that make any AI useful inside a company, so they are worth knowing before you choose.
- The same decision happens often. You want a place where a similar question comes up again and again, so the value shows up quickly and repeats. A decision made once a year teaches you little. A decision made fifty times a month compounds fast.
- Someone clearly owns it. The area needs a person who owns the outcome and can say what a good or bad answer looks like. Without an owner, there is no one to define what good means and no one to decide when to expand.
- The information can be put in order. The data and documents the AI will rely on should be reachable and possible to clean up, not scattered across systems no one controls. Context is only as good as the information underneath it.
When all three are present, you have a place where AI can produce a trustworthy answer, an owner who can confirm it is trustworthy, and a foundation clean enough to build on. When one is missing, the build gets harder in ways that have nothing to do with the AI itself.
What this looks like across the business
Run the common functions through these three conditions and the strong starting points become clear.
Finance often scores well on all three. Reporting and variance analysis are repeated constantly, the function has clear owners in the controller and CFO, and financial data tends to be more structured than most. The catch is that finance answers must be exactly right, so the trusted-source and review parts of the build matter more here than anywhere.
Sales is strong on frequency and ownership. Questions like which discount is approved, what a customer was promised, or which deal terms apply come up many times a day, and sales leadership owns the outcome clearly. The work is usually in getting the information in order, since deal history and customer context are often spread across systems.
Customer support is one of the most common strong starting points. The same questions arrive all the time, ownership is clear, and the answers usually live in a knowledge base that already exists. It is often the fastest place to show a visible result.
Operations varies widely. Some operational decisions repeat constantly and have clean data; others are one-off and depend on information no one has organized. Operations can be an excellent place to start or a difficult one, depending entirely on which specific decision you pick.
HR has frequent, repeated questions about policy and process, and usually clear ownership. The thing to watch is sensitivity. Much of the information is personal, so the permission rules have to be right from the start, which can make HR a more demanding first build than it first appears.
Notice that the answer is rarely a whole department. It is a specific, repeated decision inside one. "Start with finance" is too broad. "Start with quarterly variance commentary" — that is a place you can build.
The places that look tempting (but don't start here)
Two kinds of starting points draw companies in and tend to disappoint. The first is the high-visibility showcase: a flashy, novel use that would impress the board but rests on messy data or has no clear owner. This kind of project will demo well, and then, it will stall quietly.
The second is the hardest problem in the company. There is a temptation to point AI at the thing that has frustrated everyone for years.
But the hardest problem is usually hard precisely because the decision is rare, the ownership is contested, or the information is a mess, which is to say it fails all three conditions at once. It is the worst possible first build, and it can end the whole effort before it starts.
The point of the first build is not to solve the biggest problem. It is to prove the approach works and create a foundation the next area can use. Therefore, save the hard problems for when you have built the muscle to handle them.
The first choice shapes the second
Choosing well the first time does more than deliver one early win. The trusted sources, the permission rules, and the workflow connections you build for the first area become the starting point for the second. A strong first choice makes every choice after it easier. A poor one leaves you with a result you cannot build on, and you start the next area from zero.
This is why the question deserves real thought rather than a quick answer. You are not only picking where to get value first. You are picking where the company's AI foundation begins.
Pick the place where success is most likely
The best first move in company-specific AI is the one most likely to succeed and most useful to build on (not the most ambitious one). Find the specific, repeated decision that has a clear owner and information you can put in order, and start there.
Get that first choice right, and you have done two things at once: delivered a result the business can see, and laid the first piece of something the whole company can grow into.